扫二维码与商务沟通
我们在微信上24小时期待你的声音
解答本文疑问/技术咨询/运营咨询/技术建议/互联网交流

大模型并不是一项“新的技术”,其所依赖的Transformer架构早在2017年就已问世,并以“Attention is All You Need”之名震撼学术界。然而,直到2022年底,随着ChatGPT的推出,大模型才真正成为全民热议的焦点。为什么这个革命性架构经历了五年时间才迎来它的巅峰时刻?是技术准备不足,还是我们对“大模型”的理解发生了质的转变?
大模型除了是大参数、大数据、大算力的代表外,最关键的定义是,是否随着规模的不断变大,在某一刻出现了涌现效应,体验与之前截然不同,展现出了“智能化”的跃迁。
01 “大”的基础:参数、数据与算力
大模型最显而易见的特点是其规模庞大,这主要体现在三个维度:
大参数:现代大模型拥有数百亿乃至上万亿的参数。这些参数是模型的“记忆库”,存储了训练数据中的模式和规律。参数的数量直接影响模型的表达能力和泛化能力。例如,GPT-3 拥有 1750 亿个参数,这使得它能够处理复杂的自然语言任务,并生成高质量的文本。
大数据:没有足够丰富且高质量的训练数据,模型再大也无用。大模型的核心能力来自对多语言、多领域、多模态数据的学习和泛化。大规模的数据集不仅提供了更多的样本,还涵盖了更广泛的情境和背景,从而增强了模型的理解能力和适应性。
大算力:训练大模型需要强大的计算支持。分布式计算集群、专用硬件(如 GPU、TPU)以及优化算法的结合,为大模型提供了运行的基石。强大的算力不仅加速了训练过程,还使得模型能够在更长的时间内进行迭代优化,从而达到更好的性能。
然而,这些“大”只是基础。是否真正出现“智能化”的跃迁,取决于两个更深层的因素:Scaling Law(规模定律) 与涌现效应。
02 从Transformer到GPT:五年的积淀
Transformer架构的提出,为自然语言处理领域带来了革命性变化。它用“自注意力机制”解决了传统RNN和CNN难以处理长距离依赖的问题。基于这一架构的模型迅速崛起,如BERT、GPT、T5等都在各自领域取得了耀眼成绩。
然而,在早期,Transformer的潜力并没有完全被挖掘:
模型规模有限:最初的Transformer模型参数规模相对较小,性能的提升存在瓶颈。
算力不足:2017年的硬件环境和分布式计算技术,尚不足以支持大规模模型的训练。
数据不够大与杂:当时用于训练的数据集规模和多样性有限,模型能力受制于此。
这些限制导致Transformer的应用更多停留在学术领域,尽管性能优异,但远未达到通用智能的高度。
转折点出现在2018年之后:人们开始尝试用Scaling Law来分析并指导模型扩展的方向,进而发现了模型规模增长背后的潜在规律。
03 Scaling Law:揭开“越大越强”的秘密
Scaling Law(扩展定律)的核心在于揭示模型性能与规模之间的关系。研究表明,模型性能随参数、数据量和算力的增加呈现出近似幂律增长。这意味着,大模型不仅更强大,而且这种增长在某些条件下是可预测的。
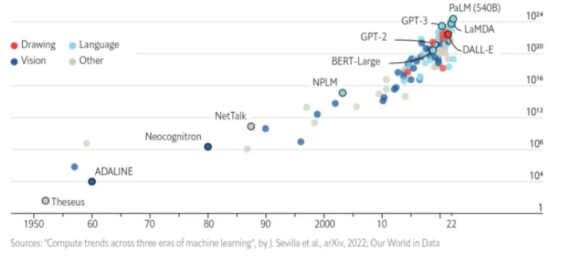
具体来说:
更多参数→更强能力:参数规模越大,模型对复杂语言模式的捕捉能力越强。
更多数据→更好泛化:训练数据的质量和多样性直接影响模型的跨领域能力。
更高算力→更快突破:算力的增加使得训练更大规模模型成为可能,同时减少了训练时间。
Scaling Law给出了明确的指导:只要数据充足、算力到位,模型规模的增加将带来可预期的性能提升。这一规律为大模型的开发提供了理论支持,也解释了为什么从GPT-2到GPT-3之间的参数扩展(从15亿到1750亿)带来了质的飞跃。
04 涌现效应:大模型的“灵魂时刻”
如果说Scaling Law解释了“大模型越大越强”,那么涌现效应则揭示了为什么“大模型”会突然变得“智慧”。
什么是涌现效应?
涌现效应(Emergence)是一种非线性现象,指当模型规模达到某个临界点后,突然表现出远超线性扩展的新能力。例如:
零样本学习:无需提供示例,模型能够基于提示完成新任务。
复杂推理能力:在跨领域推理任务中展现出强大的问题解决能力。
更自然的交互:用户与模型的对话不再机械,而是带有深度语义理解。
这些能力的出现,并非随着规模逐步增长,而是在某个规模临界点上突然涌现,这正是GPT-3.5和GPT-4等大模型让人耳目一新的根本原因。
为什么涌现效应迟到了?
涌现效应并不是Transformer架构的独特属性,而是大模型规模和复杂度积累的结果。它的“迟到”是因为以下几个因素:
模型规模不足以触发临界点:早期的Transformer模型规模相对较小,未能达到涌现效应的关键规模。
数据质量和多样性不足:高质量的多领域数据对于涌现效应至关重要,而这在2017年时尚不充分。
硬件和算法优化的滞后:分布式训练技术和硬件的发展,使得超大规模模型训练在几年后才成为可能。
2022年底的ChatGPT(基于GPT-3.5)是一次“量变到质变”的标志性事件。它的出现标志着大模型终于触发了涌现效应,进入了“智慧化”的新阶段。
05 从“迟到”到未来:大模型的下一步是什么?
今天的大模型已经展现了Transformer架构的巨大潜力,但它的进化并未停止。未来,可能会有以下几个方向:
优化Scaling Law的效率:通过稀疏激活和参数共享,在更小规模下实现类似能力。
理解涌现规律:探索涌现效应背后的机制,设计更具“智能跃迁”潜力的模型。
多模态扩展:结合图像、视频等多模态数据,让大模型具备真正的跨模态智能。
个性化与效率化:让模型既能泛化处理任务,也能针对特定用户需求提供定制化服务。
06 结语:从架构到智能,探索未止步
Transformer的诞生与大模型的兴起,是人工智能历史上的一次双重革命。它不仅改变了我们对语言的理解方式,也引发了对智能本质的更深层次思考。
从2017到2022,大模型“迟到了”五年,但它的到来以涌现效应为标志,为人工智能的发展开辟了新的篇章。理解Scaling Law与涌现效应的背后逻辑,将帮助我们更好地把握大模型的未来方向。
大模型的意义,不仅是“大”,更是“跃迁”——从量变到质变,从工具到智慧。
文章来源:@产品哲思

我们在微信上24小时期待你的声音
解答本文疑问/技术咨询/运营咨询/技术建议/互联网交流
移动版官网